爬虫网是什么?带你了解网络数据采集的那些事!

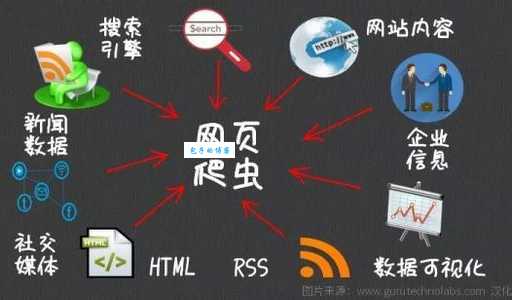
今天跟大家伙儿唠唠我是咋弄爬虫的,就是那个在网上到处爬来爬去,抓数据的玩意儿。这东西有啥用?简单说,就是能帮你自动从网上把信息扒下来,省得你一个个网页去点,眼睛都看花。...
今天跟大家伙儿唠唠我是咋弄爬虫的,就是那个在网上到处爬来爬去,抓数据的玩意儿。这东西有啥用?简单说,就是能帮你自动从网上把信息扒下来,省得你一个个网页去点,眼睛都看花。
我对这玩意儿也是一头雾水,不知道从哪儿下手。后来我想,咱的目标不就是从网上弄点数据下来吗?那咱就先找个网站试试手呗。
我得选个工具不是?现在搞爬虫的,基本上都用那个叫什么来着...对,Python!这玩意儿好使,工具多,啥都能干。我先在电脑上装个Python,然后找几个顺手的库,像那个requests,就是专门用来发送网络请求的;还有那个Beautiful Soup,能帮我把网页代码理顺,方便我找出想要的信息。
安装好这些,我就开始琢磨怎么用。第一步,我得先用requests库去访问目标网站,把网页内容给下载下来。这一步不难,就几行代码的事儿。我随便找个网站,试试,还真把网页内容给弄下来,就是一堆乱七八糟的代码,看着头疼。
就轮到Beautiful Soup上场。我用它把这些代码好好“按摩”一番,这下看起来顺眼多。然后,我就开始在里面找我想要的信息。比如说,我想把某个网站的新闻标题都给弄下来,那就得先看看这些标题在网页代码里长啥样,有什么特征。这就像是在玩“找不同”,得有点耐心。
比如新闻标题附近都有哪些类似的html标签,把他们都列出来。
看这些标签的class是不是类似。
找到新闻标题的统一规律。
找来找去还真有类似的地方,新闻标题都在类似名字的标签中,而且class还都一样,这下有规律,写几行代码一试还真找到新闻标题。找到规律后,我就写几行代码,让Beautiful Soup帮我把这些标题一个个都揪出来。搞定!标题都乖乖地排好队,等着我检阅。
这只是最简单的例子。实际情况可能比这复杂多,比如有的网站可能会阻止你这么干,或者数据藏得很深,不好找。这时候就得想别的招,比如模拟人的操作,或者用一些更高级的工具。这个先不说,要不太复杂,咱慢慢来。
我把这些抓下来的标题存到本地的文件里。以后想看的时候,直接打开文件就行,方便得很。
总结
这么一通操作下来,我也算是入门。虽然过程有点曲折,但结果还是挺让人满意的。这爬虫,就像是个不知疲倦的小助手,能帮我干不少事儿。以后我还得多琢磨琢磨,让它变得更厉害!
今天就先分享到这儿,希望对大家有所帮助。记住,实践出真知,多动手试试,你也能成为爬虫高手!